| |
深度学习是人工智能 (AI) 中发展迅速的领域之一,可帮助计算机理解大量图像、声音和文本形式的数据。利用多层次的神经网络,现在的计算机能像人类一样观察、学习复杂的情况,并做出相应的反应,有时甚至比人类做得还好。这样便提供了一种截然不同的方式,用于思考数据、技术以及人类所提供的产品和服务。
智能是各行业之所欲
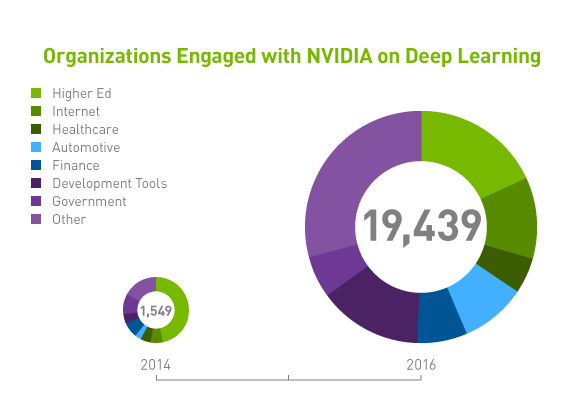
通过改进机器学习算法和升级计算硬件,各个行业中有远见的公司都在采用深度学习技术来处理爆炸性增长的数据量。这帮助他们找到新方法来利用随手可得的数据财富开发新产品、服务和流程,从而创造巨大的竞争优势。 |
 |
所以说简单点,要提升人工智能的水平,关键之处还是在于计算能力、GPU技术水平的提升。而就在本次GTC上,NVIDIA也发布了全新的下一代GPU计算加速卡Tesla P100。在主题演讲中,黄仁勋用“奇迹(MIRACLES)”来形容Tesla P100带来的改变,全新的Pascal架构、16nm制程、HBM2显存架构(提供高达720GB/s的超高带宽)、支持NVLink技术和全新的AI算法,支持高达21.2 Teraflops的峰值FP 16运算性能。
除此之外,针对深度学习领域,NVIDIA还重磅发布了全球第一款基于Tesla P100打造的面向深度学习的专用设备。相比传统的双路至强平台,Tesla P100在性能上提升了近60倍,节点带宽提升了10倍以上,训练时间缩短75倍。根NVIDIA针对13.3亿照片进行训练的测试结果显示,相比去年发布的Maxwell产品在性能提升上达到了12倍。
毫无疑问,以深度学习为代表的高性能计算领域近年来确实受到了越来越多人的关注。可以预见的是包括NVIDIA,以及围绕在其周边的产业伙伴正在针对性的做一些解决方案,以应用为主的一方则在考虑如何更好地优化、提升。随着双方
的不断精进,未来像AlphaGo战胜李世石的事情会越来越多,那时我们或许考虑的将不再是语音识别、图片搜索、无人驾驶等改善生活方式的。
计算性能的指数级增长
加速科学发现、可视化大数据以供获取见解以及为 消费者提供智能服务,这些都是研究人员和工程师们 的日常挑战。解决这些挑战需要更为复杂且精准的 模拟、对于大数据的强大处理能力或是训练复杂精妙 的深度学习网络。这些工作负载还要求提升数据中心速度,以满足对指数级计算能力的需求。
选择合适的 NVIDIA® Tesla ® 解决方
|
Tesla P100 PCIe

|
HPC 和深度学习 |
用于 HPC 和深度学习的
单个 P100 服务器可替代
32 个 CPU 服务器 |
|
> 4.7 TeraFLOPS 双精度性能
> 9.3 TeraFLOPS 单精度性能
> 720 GB/s 内存带宽(540 GB/s
型可选)
> 16 GB H |
|
每节点 2-4 GPU |
|
Tesla P100 搭载
NVLink

|
深度学习训练 |
10 倍于上代 GPU 的深度学习训练速度 |
|
> 21 TeraFLOPS 半精度性能
> 11 TeraFLOPS 次单精度性能
> 160 GB/s NVIDIA NVLink ™
> 多 GPU 高速互联
> 720 GB/s 内存带宽
> 16 GB HBM2 内存 |
|
每节点 4-8 GPU |
|
Tesla P40
|
深度学习训练和推理 |
40 倍于 CPU 服务器的
深度学习推理速度 |
|
> 47 TOPS INT8 推理性能
> 12 TeraFLOPS 次单精度性能
> 24 GB GDDR5 内存
> 1 个视频解码和 2 个视频编码引擎 |
|
每节点至多 8 GPU |
|
Tesla P4

|
深度学习推理和视频转码 |
在推理方面 40 倍于 CPU的能效 |
|
> 22 TOPS INT8 推理性能
> 5.5 TeraFLOPS 单精度性能
> 1 个视频解码和 2 个视频>
编码引擎
> 50 W/75 W 功耗
> 半高外形 |
|
每节点 1-2 GPU |
|
机器学习工具
· Caffe: 用于脑回神经网络算法的架构
· cuda-convnet: 脑回神经网络的高性能 C++/CUDA 软件实施
· Theano: 用于定义、优化以及评估数学公式的 Python 库
· Torch7: 用于机器学习算法的科学计算架构
· cuBLAS: GPU 加速版本的完整标准 BLAS 库
· MATLAB: 简单易用的 HPC 语言集成计算、可视化以及编程
· cxxnet: 神经网络工具包
NVIDIA Tesla P100 是能够推动 AI 革命和实现 HPC突破的计算引擎。例如,纽约西奈山伊坎医学院(IcahnSchool of Medicine at Mount Sinai)的研究人员使用深度学习分析 100,000 多名患者的健康记录,以预测患者可能的疾病发展,可至多先于传统诊断一年的时间为患者给出治疗方案。

AI 预测和预防疾病西奈山医学院使用深度学习可在病情确诊前确认高危险患者,从而
为医生提供拯救性命的先机。 |
 |
| 产品型号 |
|
| 机箱规格 |
| |
-4U机架式
-3,200W(2+1)200-240Vac输入
-30.31“x 17.24”x 6.93“(770 x 438 x 176mm) |
|
| 芯片组 |
| |
-英特尔® C612 芯片组
-PCH控制器
-每个处理器配置集成内存控制器
-英特尔® 快速通道互连:高达9.6 GT/s |
|
| CPU处理器 |
| |
-2x Intel® Xeon® Processor E5-2660 v4
-单颗14核心,28线程,2.0GHz主频,功耗(TDP)105W |
|
| 内存 |
| |
-1024GB DDR4 Memory installed |
|
| GPU处理器 |
| |
-8x NVIDIA® TESLA® P100(支持全系列 NVIDIA GPU 卡)
> 21 TeraFLOPS 半精度性能
> 11 TeraFLOPS 次单精度性能
> 160 GB/s NVIDIA NVLink™
> 多 GPU 高速互联
> 720 GB/s 内存带宽
> 16 GB HBM2 内存 |
|
| 存储 |
| |
-1x Intel S3520 800G SSD SYSTEM DISK
-8X 希捷 SATA 3.5寸接口 10TB 企业级硬盘ST10000NM0016 |
|
| 系统OS |
| |
-软件 Ubuntu 16.04 操作系统、专用的 GPU 驱动程序(用于测试工作站是否安装正确) |
|
板载显卡和
网卡 |
| |
-2x 10GbE端口(1个端口与IPMI共享)
-英特尔X540-AT2
-板载显卡控制器 |
|
| I / O端口 |
| |
-1 DVI/DisplayPort, 2 Gbit LAN, 4 USB 3.0 |
|
| 扩展槽位 |
| |
- (8)PCI-E Gen3 x16插槽/(2)PCI-E Gen3 x8插槽(一个用于夹层卡)/(3)PCI-E Gen2 x1插槽 |
|
| 服务器管理 |
| |
-IPMI 2.0兼容的基板管理控制器(BMC)/支持通过IP和远程平台闪存/ USB 2.0虚拟集线器的存储 |
|
| 软件 |
| |
NVIDIA Digits, Caffe, Torch, Theano, BIDMach, cuDNN, OpenCV, NVIDIA® CUDA®
Toolkit, Google TensorFlow, and MXNet as standard. Automatic software update
tool included. Custom software installs possible on request. |
|
|
